REST API: How to avoid duplicate resource creation on concurrent requests.
Dealing with concurrent HTTP requests and how to handle them to maintain the integrity of the data.
Software Engineer with over a decade of experience in building monolithic to microservices with PHP, Java (Spring), JavaScript (Node, Vue), Erlang/Elixir (Phoenix), Search engineering (Solr, Elasticsearch), Cloud (AWS).

Source: http://www.juimg.com/shiliang/201904/anniutubiao_1768500.html
As anyone working as a software engineer, we all might have come across dealing with API's in our lives. It's easy to consume them, however, designing one requires lots of experience and requires diligent effort and rigorous testing. Also, one of the topics which are always ambiguous in API design is Idempotency, which HTTP verbs are considered to be Idempotent, and which are not, and having that knowledge helps build effective APIs.
We are not going to delve into the Idempotency topic today, the topic is for another day :-). If you would like to explore further, here are some interesting articles
https://developer.mozilla.org/en-US/docs/Glossary/Idempotent
https://developer.mozilla.org/en-US/docs/Glossary/Idempotent
Preamble
In part of this write-up, I'm going to explore a problem I ran into dealing with concurrent requests which resulted in creating multiple resources with the same data, especially since such a problem is very critical if we are dealing with payments.
Problem
I was working on an integration with external payment gateway providers with their API for accepting payments into our system. As part of the gateway integration, we needed to provide a callback URL for the payment provider to a callback for the payment transaction state (was it successful, failed, rejected etc). End-to-end integration went well and we covered the happy path of accepting payment with all statuses.
However, At one point, we needed to test a transaction which was successful from the client side, and break the connection so that we did not get an immediate callback from the payment provider. Usually in such scenarios, Payment providers eventually call back at certain intervals to make sure our sever state for the transactions is processed correctly, and update the payment status accordingly. At a certain interval, we did get a callback from the payment provider, however, to our surprise, we got multiple callbacks for the same successful payment payload.
In the application, we end up having multiple records for the same payment and ended up updating users' payments multiple times (the number of times we got the callback requests). Imagine, the user wants to topup $100 and ended up having $300 in their wallet. In such scenarios, we can not possibly control external or third-party APIs and how they are designed. They might have retried or used a queue mechanism or reposted the resources accidentally.
Dealing with such a design will be crucial if we are dealing with payments or mission-critical applications.
Problem in detail
Let’s take an example of an application integrating with a payment gateway. Each customer who comes to our app uses to select the payment gateway of their choice to pay for a subscription. Internally in our API, we send a request to the payment gateway to create a new payment (POST /api/payments/payment). If the transaction is successful, we get status successful status from the Payment gateway with transaction details, and the transaction is recorded in our DB. This is the sweet, ideal scenario as shown in the below illustration.

On the other hand, if we encounter any network issues while waiting for the payment gateway to acknowledge us, there is no way to find out if the payment was successful or not as illustrated below.
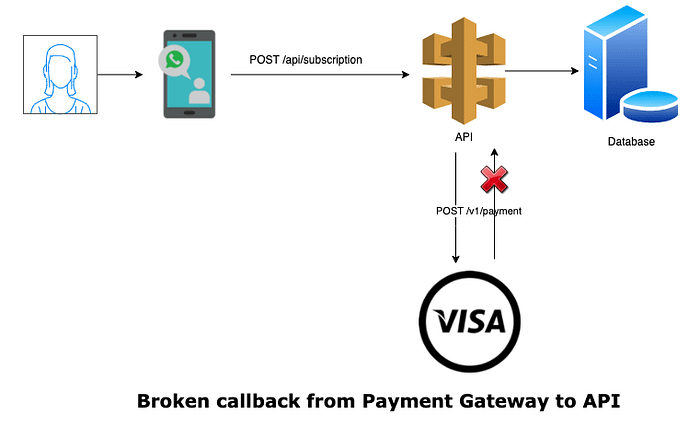
After a while, the said payment gateway decided to callback our API to update the broken payment transaction. These calls could come in many means, could be by manually requesting the payment status or retries from the payment gateway itself or automatic callbacks. And if we do not have a proper method to check for duplicate transaction records in our database, we might end up updating customer payment as many times as we got the request from the gateway. How do we make sure we do not capture multiple payment records for the same transaction?
There is always more than one right way.
Solutions
Ideally, most of us already know how to deal with such operations. I will try to elaborate on the methods I applied and the outcome of each method and why I choose to go with a certain method.
Method 1: Data Validation
Customer payment transactions are recorded in a table called payments. The structure of the table looks like
CREATE TABLE `payments` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_id` varchar(50) NOT NULL DEFAULT '',
`status` varchar(10) NOT NULL DEFAULT '',
`amount` decimal DEFAULT NULL,
`transaction_id` varchar(50) DEFAULT NULL,
`gateway_response` json DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Each time get a response or callback from the payment gateway, query the DB to check if there is an existing transaction for the same user with similar order_id
SELECT * from payments where user_id = ? and order_id = ?;
Pseudocode for the payment validation looks like
const payment = getPayment(userId, orderId);
if (payment) {
print 'Payment already exists!. Must be duplicate payment'
throw Error('duplicate') or return;
}// elsevar newPayment = createPayment(userId, reqParams)
The problem with this method is that, when we are swamped with concurrent requests with the same payload in a matter of seconds, we still can not avoid duplication. Because it takes time to query and get the response from DB and during that period, we could have created multiple payment records already.
Method 2: Locking (Mutex) Mechanism
According to Wikipedia's definition
In computer science, a lock or mutex (from mutual exclusion) is a synchronization primitive: a mechanism that enforces limits on access to a resource when there are many threads of execution. A lock is designed to enforce a mutual exclusion concurrency control policy, and with a variety of possible methods, there exist multiple unique implementations for different applications. - Wikipedia
It is a well-known mechanism that certainly could be applied in many cases, however, not when we are dealing with concurrent requests.
Implementation is quite similar to the above method, however, instead of DB, we could choose to implement this in in-memory data stores such as Redis.
Pseudocode for the locking the payment to avoid duplication looks like
// make a unique reference key for each payment transaction
var paymentKey = 'PAYMENT' + user_id + order_id
var payment = getPayment(paymentKey) // assume that this method calls redis or any other in-memory store to get the key
if (payment) {
print 'Payment already exists!. Must be duplicate payment'
throw Error('duplicate') or return;
}setPayment(paymentKey) // assume that this methods sets the new payment reference in in-memory
var newPayment = createPayment(userId, reqParams)
From the above pseudocode, when we get the first request, we set the reference in in-memory and create the payment record. And for the subsequent payment records for the same transaction, we ignore them.
Unfortunately, even with this method, a query to in-memory was slow enough to record multiple payment records and still could not avoid duplicates
Here are a few interesting articles regarding locking mechanisms to explore.
https://stackoverflow.com/questions/129329/optimistic-vs-pessimistic-locking https://blog.couchbase.com/optimistic-or-pessimistic-locking-which-one-should-you-pick/
Method 3: Queuing
I did not try this approach since I did not have any queues implemented in the application. However, this could be a more reliable method and gives more flexibility for the application to deal with concurrent requests.
The idea here is to queue all the incoming requests into a queue and deal with them slowly using a consumer and validate each incoming request to make sure we capture only one request.
Method 4: Database table with composite UNIQUE constrain
In this method, we design the payments table with a composite unique key that ensures we have a unique record for each payment. The table design is as follows
CREATE TABLE `payments` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_id` varchar(50) NOT NULL DEFAULT '',
`status` varchar(10) NOT NULL DEFAULT '',
`amount` decimal DEFAULT NULL,
`transaction_id` varchar(50) DEFAULT NULL,
`gateway_response` json DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_payment_transaction` (`user_id`,`order_id`,`status`),
KEY `user_id` (`user_id`),
KEY `order_id` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Note: The DB structure I’m using here is MySQL, the structure may differ from other RDBS systems
From the above table schema, I made a composite key out of (user_id, order_id, status)
If we get the same payment request for the same order for a user, In MySQL, we would only have one row recorded, and for the subsequent insertion, MySQL throws a Duplicate entry error. In the application, we can either throw the error or explicitly capture the error from the DB engine and show a meaningful error message to the user.
I chose to go with this approach since it's more efficient than method 1 and 2 and it guarantees that there will not be duplicates and does not require to implementation of extra validation nor requires to use of any in-memory data stores.
Those who are resorting to NoSQL systems might need to look to the first three methods. Method 1 and 2 are not so efficient and queuing methods be the best option if your infrastructure supports them. I do not prefer to go with NoSQL databases as my primary data stores :-) but they are preferable choices as secondary storage.
Here is the GitHub Repo that demonstrates the Method 4 implementation written in NodeJs.
If there are other ways to deal with such operations, please feel to share, would love to get to know different ways of solving such operations.